Aşağıda anlatacağım projede örnek olması için ekşi sözlükten veri çekeceğim. Bu proje sadece öğrenme ve öğretme amaçlı yazılmıştır kötü niyetle kullanmayalım.
Projeye başlamadan önce bilmemiz gereken birkaç şey var. Öncelikle bunlara bakalım.
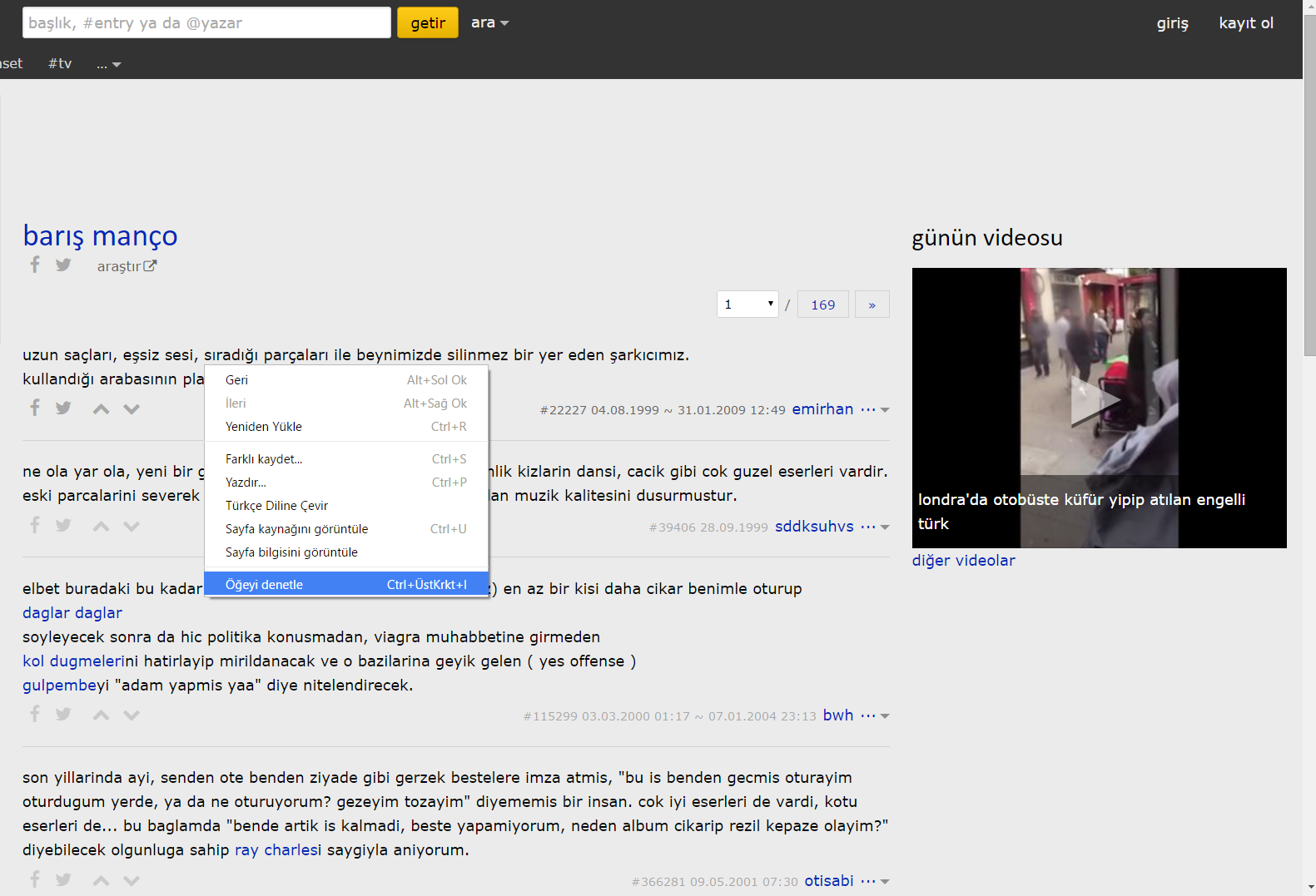
Bir web sitesinden XPath yolunu nasıl alınız?
Bunu da ekşi sözlük üzerinden gösteriyorum.Ekşi sözlükte herhangi bir konuya giriyoruz ve ilk entrye sağ tıklayıp ögeyi denetleye giriyoruz. Daha sonra açılan pencereden ilk entrynin üzerine gelip copy XPath diyoruz. Böylece ilgili entrynin XPath komunun alabiliyoruz.

C# StreamReader ve StreamWriter Sınıfları nasıl kullanılır?
Buna çok basit bir not defteri yaparak proje üzerinde bakalım.
Yeni bir Form oluşturup 1 textbox 2 tane de buton ekliyoruz.
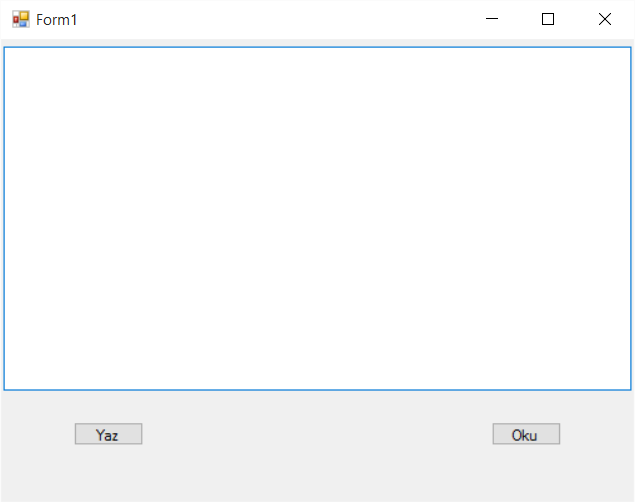
Daha sonra butonların click eventlerine kodlarımızı yazıyoruz.
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.IO; //StreamWriter ve StreamReader sınıflarını kullanmak için ekliyoruz.
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
namespace WindowsFormsApplication1
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
private void btnYaz_Click(object sender, EventArgs e)
{
/*
* StreamWriter sınıfından writer isimli nesneyi türetiyoruz ve parametrelerinden
* ilkine dosya yolumuzu ikincisine ise true diyoruz. true yazmazsak her seferinde
* oluşturulan metin belgesini siler ver yeniden yazar.
*/
StreamWriter writer = new StreamWriter("dosya.txt",true);
writer.WriteLine(tbMetin.Text);
/*
* işimiz bittikten sonra writer nesnemizi kapatıyoruz. Aksi takdirde ikinci bir yazma
* veya okuma işleminde hata alırız.
*/
writer.Close();
}
private void btnOku_Click(object sender, EventArgs e)
{
StreamReader reader = new StreamReader("dosya.txt");
tbMetin.Text=reader.ReadToEnd();
reader.Close();
}
}
}
Şimdi projemize başlayabilriz. Öncelikle HtmlAgilityPack kütüphanesini kullanabilmek için projemize import etmemiz gerekiyor. Daha sonra namespacede tanımlama yapıyoruz.
using HtmlAgilityPack;
Bize 3 tane metod lazım. Bunlardan birincisi gireceğimiz ekşi sözlük konusunda kaç sayfa entry olduğunu hesaplayacak. İkincisi bu sayfalardaki entryleri çekecek. Üçüncüsü ise çekilen entryleri bir metin belgesine kaydedecek.
string count;
string calculatePageCount(string url)
{
WebClient wClient = new WebClient();
wClient.Encoding = System.Text.Encoding.UTF8;
string webSite = wClient.DownloadString(url);
HtmlAgilityPack.HtmlDocument hd = new HtmlAgilityPack.HtmlDocument();
hd.LoadHtml(webSite);
HtmlNodeCollection hnc = hd.DocumentNode.SelectNodes("//*[@id=\"topic\"]/div[2]");
foreach (HtmlNode hn in hnc)
{
count = hn.Attributes["data-pagecount"].Value;
}
return count;
}
//Metodumuz parametre olarak sadece içeriğin çekileceği urli alır.
void downloadData(string url)
{
string text; //text isimli string bir değişken oluşuturuyoruz.
WebClient wClient = new WebClient(); //webclientimizi oluşturuyoruz.
/*aşağıdaki for döngüsünün 1'den 10'a kadar dönmesinin sebebi
ekşi sözlükte her sayfada 10 entry bulunduğu için*/
for (int i = 1; i <= 10; i++)
{
//WebClient nesnemize encoding işlemi yapıyoruz çünkü indirdiğimiz datadaki türkçe karakterler sıkıntı yaratıyor
wClient.Encoding = System.Text.Encoding.UTF8;
//girilen urli tamamen indiriyoruz
string webSite = wClient.DownloadString(url);
//nesnemizi oluşturuyoruz.
HtmlAgilityPack.HtmlDocument hDocument = new HtmlAgilityPack.HtmlDocument();
//indirdiğimiz datayı aktarıyoruz.
hDocument.LoadHtml(webSite);
//Aşağıda yapılan işlemleri anlamak için XPath nasıl kullanılır bunu bilmemiz gerekiyor.
//Öğrenmek için aşağıdaki adrese göz atabilirsiniz.
//http://www.buraksenyurt.com/post/XPath-ve-Net-bsenyurt-com-dan.aspx
HtmlNodeCollection hnCollection = hDocument.DocumentNode.SelectNodes("//*[@id=\"entry-list\"]/li[" + i + "]/div[1]");
foreach (HtmlNode hn in hnCollection)
{
text = hn.InnerText;
//writeData metodu ile çektiğimiz verileri tek tek metin belgesine kaydediyoruz.
writeData(text);
}
}
//Bu metot çektiğimiz veriyi metin belgesine kaydeder.
void writeData(string data)
{
StreamWriter writer = new StreamWriter("dosya.txt", true);
writer.WriteLine(data);
writer.Close();
}
public Form1()
{
//Url adresini ben aşağıda elle verdim siz isterseniz formda textboxtan alabilirsiniz.
string url = "https://eksisozluk.com/senol-gunes--91730";
//Aşağıda yazdığımız metot sayesinde sayfa sayısını alıyoruz.
string pageCount = calculatePageCount(url);
//Döngümüz 1'den sayfa sayısına kadar dönecek.
for (int i = 1; i <= Convert.ToInt32(pageCount); i++)
{
//Aşağıda if else dallanması yapmamın nedeni ekşi sözlüğün parametreleri ile alakalı.
//Döngü ilk çalıştığında if bloğuna düşer.
if (i == 1)
downloadData(url);
else
{
/*Aşağıda ekşi sözlüğün parametre değerlerine göre yeniden urlmizi belirliyoruz.Örneğin;
https://eksisozluk.com/cnbc-e--91396 linkimiz döngü ikinci kez çalıştığında şu şekilde
olur https://eksisozluk.com/cnbc-e--91396?p=2 böylece konunun ikinci sayfası açılmış olur*/
string newUrl = url + "?p=" + i;
downloadData(newUrl);
}
}
}
Bir yanıt yazın